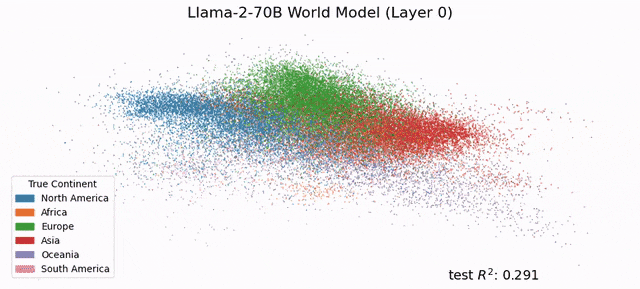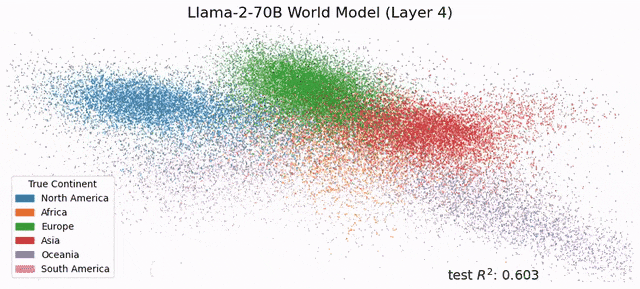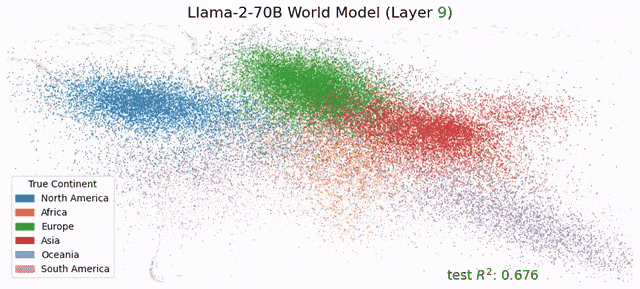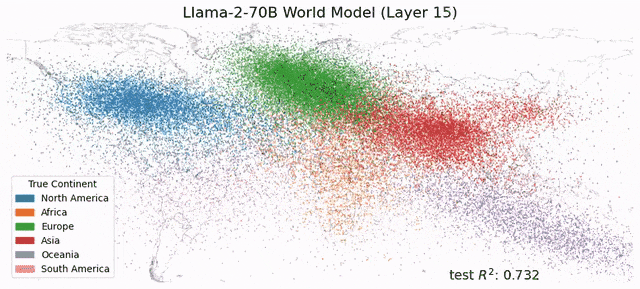
再过两周,黄仁勋将站上GTC 2026的舞台。
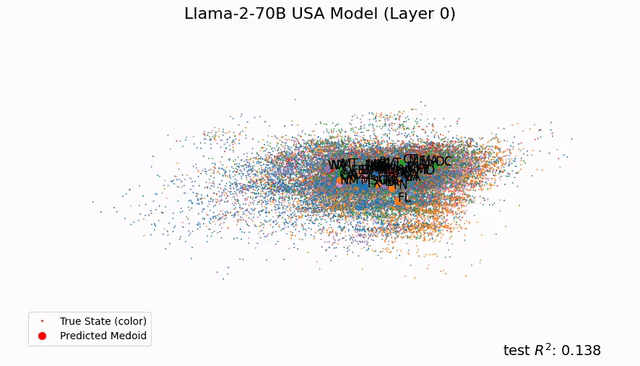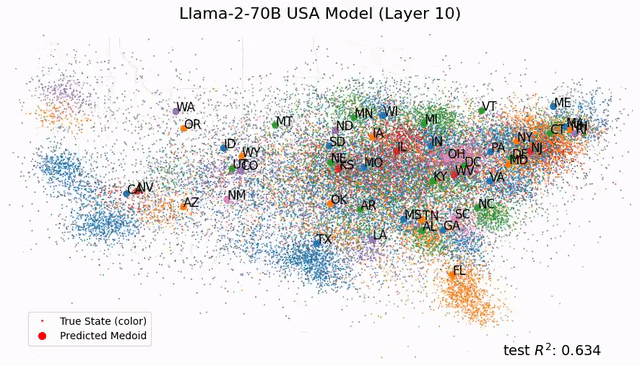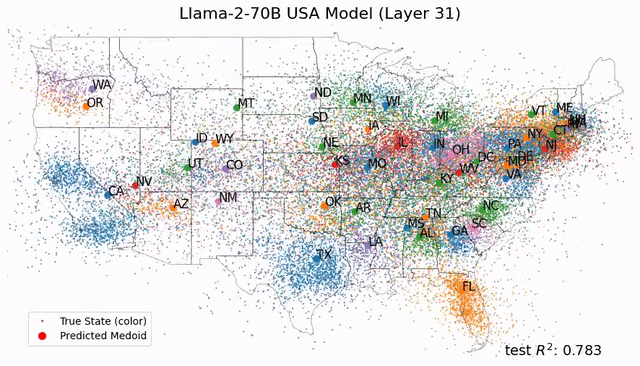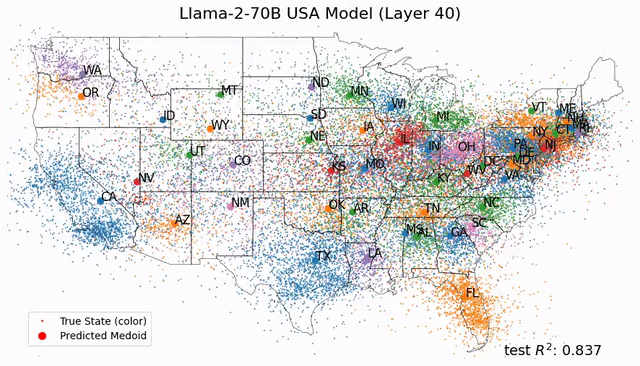
他提前放了话:「我们准备了几款世界上前所未见的全新芯片。」
底气来自一份炸裂的成绩单——
英伟达2026财年年收入2159亿美元,净利润翻倍,数据中心业务三年翻了13倍。
在财报电话会上,CFO直接甩出一个数字:客户已经部署了9吉瓦的Blackwell基础设施!
但诡异的一幕出现了。
财报发布当晚,英伟达盘后一度涨超4%。随后股价悄然转跌,次日直接低开低走,收跌5.46%,一夜蒸发数千亿美元市值。
华尔街不是看不懂数字,是看懂了趋势。
前有Anthropic甩出210亿美元订单,全面采购基于谷歌TPU的算力系统;后有Meta跟谷歌签下数十亿美元芯片大单,大规模租用TPU训练模型。
为了给编程带来接近实时的响应体验,OpenAI更是历史上首次将主力级产品GPT-5.3-Codex-Spark,部署在了更低延迟与更低能耗的非GPU芯片Cerebras上。
英伟达最大的几个客户,正在集体分散筹码。
全球AI芯片中GPU架构和非GPU架构比例(数据来源:高盛全球投资研究部)
根据摩根大通的产能报告,谷歌计划在2027年部署600至700万颗TPU,大部分供给Anthropic、OpenAI、Meta和苹果等外部客户。
高盛投资研究部的模型显示,全球AI服务器中非GPU芯片出货占比,将从2024年的36%升至2027年的45%。
类似的,IDC也预测,到2028年,中国非GPU服务器市场规模占比将逼近50%。GPU的致命短板
一个更深层的转折正在发生:AI的竞争焦点,正从单纯的算力规模,转向对能效比与延迟的极致追求。
过去拼谁卡多、谁集群大。
现在拼的是,同样花一块钱,谁能吐出更多Token。
「每美元产生的Token数」正在取代峰值算力,成为衡量芯片商业价值的核心指标。
究其原因在于,GPU的架构决定了,每次计算时数据都要在外部显存和计算单元之间来回搬运。
路径长、次数多,能耗就高、延迟就大。堆更多卡解决不了这个问题。
路透社爆料,OpenAI已多次表达对英伟达芯片的「不满」——响应速度没达预期,在代码生成产品Codex上感受尤为明显。
压力迫使英伟达这条「巨龙」寻求改变。
图灵奖得主David Patterson教授在最新研究中指出,大模型每次token生成都绕不开数据搬运,而搬运能耗远高于计算本身。
未来的核心命题是「让数据离计算更近」。
为此,他给出了三个AI芯片的演进方向:近内存处理、3D堆叠、低延迟互连。
实际上,这些都指向同一件事——用架构创新降低数据搬运的能耗和延迟。
换句话说就是,谁能用更低的能耗、更低的延迟跑通下一代模型,谁就能在未来十年的算力牌桌上占得先机。谷歌TPU杀向商用市场
一直以来,谷歌TPU专供自家大模型训练和推理,外人用不到。
去年开始,谷歌把TPU推向了商用。
订单随即涌入。
博通CEO透露,Anthropic下了210亿美元的大单;Meta签下数十亿美元TPU租赁协议;潜在客户还包括苹果和已与SpaceX合并的xAI。
原因不难理解。大模型进入规模化落地阶段,算力需求爆发、成本压力加剧,单一依赖GPU的瓶颈越来越明显。而谷歌TPU的性能,已经具备与顶级GPU分庭抗礼的实力。
2025年推出的第七代TPU,是谷歌迄今为止性能最高、可扩展性最强的AI芯片——
单芯片峰值算力4614 TFLOPS(FP8精度),最大集群9216颗芯片、总算力达42.5 EFLOPS。
划重点:TPU v7在同等算力输出下功耗仅为英伟达B200的40%至50%。
不仅如此,谷歌自研的光电路交换机(OCS)技术,还让万卡级集群实现近乎线性的加速比。相比之下,传统GPU集群规模越大,通信损耗越严重;而TPU集群基本不吃这个亏。
Google TPU v5e、v5p、v6、v7芯片关键性能对比
谷歌TPU崛起还有更为直接的例证:在TPU上训练的Gemini 3,在多个权威基准测试中位居榜首,为业界顶尖模型之一。
回到成本账上。
TPU凭借AI专用架构带来的2-4倍能效优势,将大模型推理的综合成本相比GPU拉低50%以上。而这正是Anthropic、Meta们用订单投票的根本逻辑。
当下,大多数大模型企业已经在用TPU+GPU的组合来缓解成本压力。
去年11月,半导体研究机构SemiAnalysis对比大模型公司的采购成本后发现:与OpenAI相比,同时使用TPU与GPU的Anthropic,在与英伟达谈判时拥有更强的议价权。
手里有TPU,就多了一张跟老黄讨价还价的牌。未来头部AI公司大概率都会走「多芯片并行」路线。
OpenAI与Anthropic购买算力的成本对比
性能跨越式提升,顶尖大模型规模化验证,头部公司主动布局——TPU已从算力产业的补充路线,升级为主流路线。
英伟达一家独大的格局,正在被改写。
十年磨一剑「TPU之父」要造下一代AI芯片
2025年底,英伟达斥资200亿美元,拿下AI芯片创企Groq的核心技术和团队。
这是英伟达史上最大的一笔交易,溢价近三倍。
Groq创始人Jonathan Ross,被称为「TPU之父」,谷歌TPU的核心设计者之一。离开谷歌后,他创立Groq的目标很明确:做一颗超越谷歌TPU的芯片。
两者的差异在架构。
谷歌TPU走的是「固定架构+集群扩展」路线。
其中,芯片内部搭载固定计算单元,依托二维数据流运算;芯片间通过3D Torus拓扑实现高效互联。架构稳定,但灵活性有限。
谷歌TPU架构
Groq的TSP(Tensor Streaming Processor)则是一种「软件定义硬件」的数据流处理器。
其核心理念是,通过构建可重构的软硬件系统,在保持可编程性的同时,达到接近ASIC的极致性能。
具体来说,芯片内部做了功能切片化微架构设计,配合软件层的灵活配置,可根据不同任务实时调整计算逻辑和数据流路径。
同时,依托大容量片上SRAM及静态调度机制,显著提升了数据访存效率并降低搬运能耗。
美国DARPA「电子复兴计划」(ERI)高度看好「软件定义硬件」方向,将其列为国家级战略核心。这也是Groq被称为「高阶TPU」的原因。
数据显示,在相同推理任务中,Groq芯片首token延迟比谷歌TPU v7降低20%至50%,每token成本降低10%至30%。这场芯片革命,才刚开始加速
Groq被收编,但「高阶TPU」的进化没停。
国内清微智能、海外Cerebras等公司正在高效数据流动态配置和先进集成方式上持续突破。
1. 通过3D Chiplet技术构建三维立体数据流架构。
具体来说,「计算核心+3D DRAM芯粒」的组合在垂直与水平两个维度上形成了高效的数据流计算模式,突破了传统二维架构的效率局限。
三维架构可以依据计算任务的需求和数据特性,在两个维度上灵活调度数据流,最大化缩短传输路径,降低搬运过程中的延迟与能耗,从而进一步提升整体计算效率。
2. 依托算力网格技术构建灵活数据流计算范式。
传统固定组网存在扩展性和语义适配瓶颈。而算力网格技术则可以通过灵活组网,实现Scale up与Scale out的协同。
根据AI任务特性,系统能实时下发数据流的动态配置信息,在多种互联拓扑结构间灵活切换、精准调度。最终降低互联延迟,充分释放数据流架构的算力。
3. 通过前沿的晶圆级芯片技术,将数据流架构的优势发挥到极致。
这项技术将数据流架构从芯片尺度扩展到整片晶圆。
在整张晶圆上高密度集成大量计算核心,计算核心间的互联距离被极大缩短。带来的结果是,互联带宽实现数量级提升,通信延迟大幅降低。
数据流架构的算力规模与计算效能由此被推到极致。这也是为什么晶圆级芯片被视为数据流计算架构的理想物理载体。
以Cerebras为例。
数据显示,Cerebras CS 3系统推理性能比英伟达旗舰DGX B200快21倍,成本与功耗均降低三分之一,在算力、成本、能效上展现出显著的综合优势。
在实测中,OpenAI的Codex-Spark跑出了每秒超1000 token的生成速度,让代码编写第一次有了实时交互的体验。
Cerebras CS-3 vs英伟达GPU:大模型推理速度对比GPU独霸的时代,回不去了
谷歌TPU走出围墙,OpenAI拥抱晶圆级芯片,英伟达天价收编Groq。
这些信号均指向同一个方向:
算力世界的单极格局正在松动。
定义下一代AI上限的,不再是单纯的算力规模,而是能耗、延迟、确定性共同构成的AI新标尺。
对于国产芯片而言,这是窗口,也是分水岭。简单复刻只能分得残羹,唯有在底层架构上走出自己的创新之路,才有资格进入下一轮博弈。